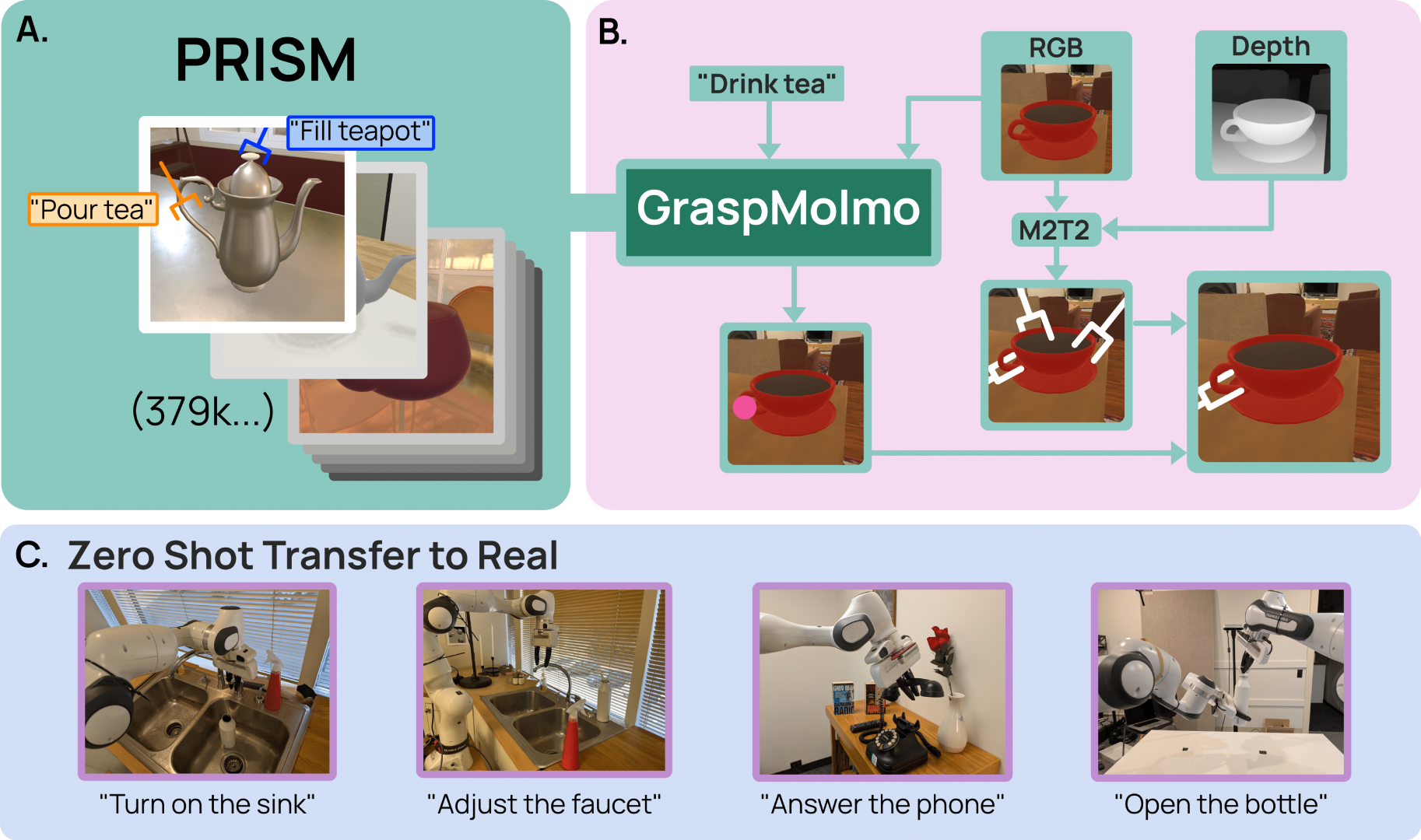
We present GraspMolmo, a generalizable open-vocabulary task-oriented grasping (TOG) model, and PRISM,
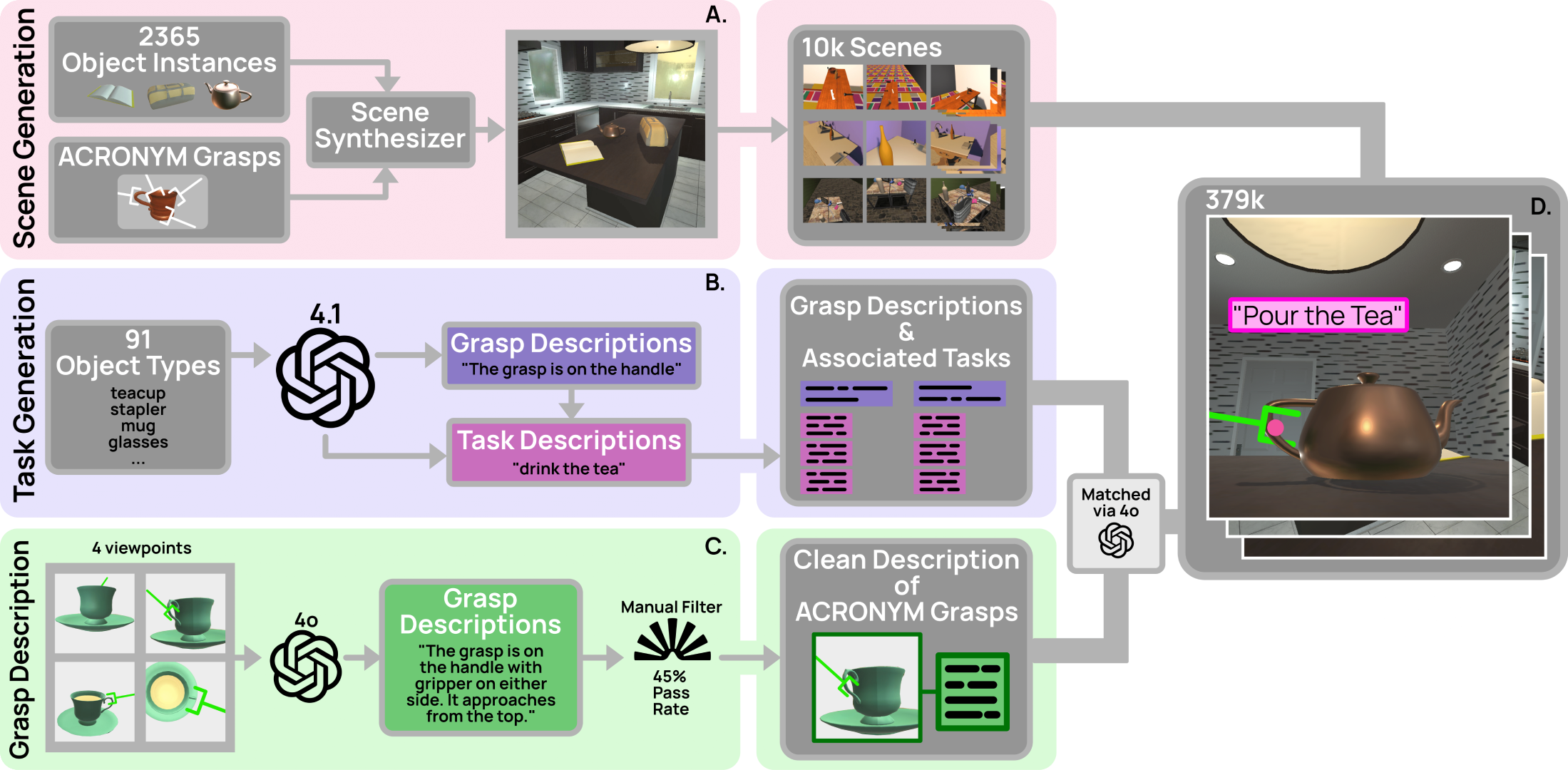
a large-scale synthetic dataset used to train it. GraspMolmo predicts
semantically appropriate, stable grasps conditioned on a natural language instruction and a single RGB-D frame.
For instance, given "pour me some tea", GraspMolmo selects a grasp on a teapot handle rather than its body or lid.
Unlike prior TOG methods, which are limited by small datasets, simplistic language, and uncluttered scenes,
GraspMolmo learns from PRISM, a novel large-scale synthetic dataset of 379k samples featuring cluttered environments and
diverse, realistic task descriptions. We fine-tune the Molmo visual-language model on this data, enabling
GraspMolmo to generalize to novel open-vocabulary instructions and objects.
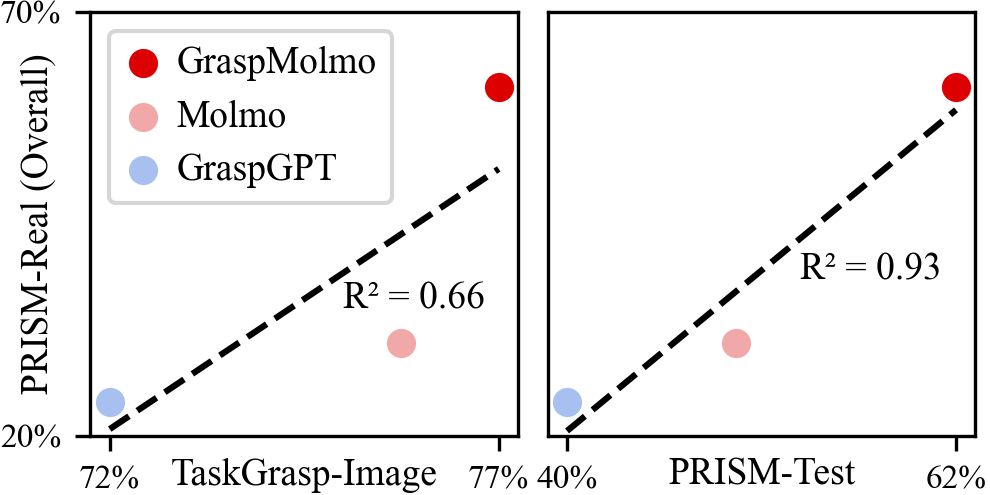
In challenging real-world evaluations, GraspMolmo achieves state-of-the-art results, with a 70% prediction
success on complex tasks, compared to the 35% achieved by the next best alternative. GraspMolmo also
successfully demonstrates the ability to predict semantically correct bimanual grasps zero-shot.
We release our synthetic dataset, code, model, and benchmarks to accelerate research in task-semantic robotic
manipulation.