Conference Papers

GraspMolmo: Generalizable Task-Oriented Grasping via Large-Scale Synthetic Data Generation
Abhay Deshpande, Yuquan Deng, Arijit Ray, Jordi Salvador, Winson Han, Jiafei Duan, Kuo-Hao Zeng, Yuke Zhu, Ranjay Krishna, Rose Hendrix
CoRL 2025
Abstract arXiv Project WebsiteWe present GraspMolmo, a generalizable open-vocabulary task-oriented grasping (TOG) model, and PRISM, a large-scale synthetic dataset used to train it. GraspMolmo predicts semantically appropriate, stable grasps conditioned on a natural language instruction and a single RGB-D frame. For instance, given "pour me some tea", GraspMolmo selects a grasp on a teapot handle rather than its body or lid. Unlike prior TOG methods, which are limited by small datasets, simplistic language, and uncluttered scenes, GraspMolmo learns from PRISM, a novel large-scale synthetic dataset of 379k samples featuring cluttered environments and diverse, realistic task descriptions. We fine-tune the Molmo visual-language model on this data, enabling GraspMolmo to generalize to novel open-vocabulary instructions and objects. In challenging real-world evaluations, GraspMolmo achieves state-of-the-art results, with a 70% prediction success on complex tasks, compared to the 35% achieved by the next best alternative. GraspMolmo also successfully demonstrates the ability to predict semantically correct bimanual grasps zero-shot. We release our synthetic dataset, code, model, and benchmarks to accelerate research in task-semantic robotic manipulation.

Data Efficient Behavior Cloning for Fine Manipulation via Continuity-based Corrective Labels
Abhay Deshpande, Liyiming Ke, Quinn Pfeifer, Abhishek Gupta, Siddhartha Srinivasa
IROS 2024 (Oral Presentation)
Abstract arXiv Project WebsiteWe consider imitation learning with access only to expert demonstrations, whose real-world application is often limited by covariate shift due to compounding errors during execution. We investigate the effectiveness of the Continuity-based Corrective Labels for Imitation Learning (CCIL) framework in mitigating this issue for real-world fine manipulation tasks. CCIL generates corrective labels by learning a locally continuous dynamics model from demonstrations to guide the agent back toward expert states. Through extensive experiments on peg insertion and fine grasping, we provide the first empirical validation that CCIL can significantly improve imitation learning performance despite discontinuities present in contact-rich manipulation. We find that: (1) real-world manipulation exhibits sufficient local smoothness to apply CCIL, (2) generated corrective labels are most beneficial in low-data regimes, and (3) label filtering based on estimated dynamics model error enables performance gains. To effectively apply CCIL to robotic domains, we offer a practical instantiation of the framework and insights into design choices and hyperparameter selection. Our work demonstrates CCIL's practicality for alleviating compounding errors in imitation learning on physical robots.
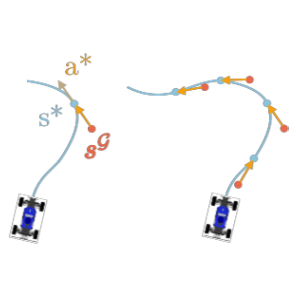
CCIL: Continuity-based Data Augmentation for Corrective Imitation Learning
Liyiming Ke*, Yunchu Zhang*, Abhay Deshpande, Siddhartha Srinivasa, Abhishek Gupta
ICLR 2024
Abstract arXiv Project WebsiteWe present a new technique to enhance the robustness of imitation learning methods by generating corrective data to account for compounding errors and disturbances. While existing methods rely on interactive expert labeling, additional offline datasets, or domain-specific invariances, our approach requires minimal additional assumptions beyond access to expert data. The key insight is to leverage local continuity in the environment dynamics to generate corrective labels. Our method first constructs a dynamics model from the expert demonstration, encouraging local Lipschitz continuity in the learned model. In locally continuous regions, this model allows us to generate corrective labels within the neighborhood of the demonstrations but beyond the actual set of states and actions in the dataset. Training on this augmented data enhances the agent's ability to recover from perturbations and deal with compounding errors. We demonstrate the effectiveness of our generated labels through experiments in a variety of robotics domains in simulation that have distinct forms of continuity and discontinuity, including classic control problems, drone flying, navigation with high-dimensional sensor observations, legged locomotion, and tabletop manipulation.
Cherry Picking with Reinforcement Learning
Yunchu Zhang*, Liyiming Ke*, Abhay Deshpande, Abhishek Gupta, Siddhartha Srinivasa
RSS 2023
Abstract arXiv Project WebsiteGrasping small objects surrounded by unstable or non-rigid material plays a crucial role in applications such as surgery, harvesting, construction, disaster recovery, and assisted feeding. This task is especially difficult when fine manipulation is required in the presence of sensor noise and perception errors; errors inevitably trigger dynamic motion, which is challenging to model precisely. Circumventing the difficulty to build accurate models for contacts and dynamics, data-driven methods like reinforcement learning (RL) can optimize task performance via trial and error, reducing the need for accurate models of contacts and dynamics. Applying RL methods to real robots, however, has been hindered by factors such as prohibitively high sample complexity or the high training infrastructure cost for providing resets on hardware. This work presents CherryBot, an RL system that uses chopsticks for fine manipulation that surpasses human reactiveness for some dynamic grasping tasks. By integrating imprecise simulators, suboptimal demonstrations and external state estimation, we study how to make a real-world robot learning system sample efficient and general while reducing the human effort required for supervision. Our system shows continual improvement through 30 minutes of real-world interaction: through reactive retry, it achieves an almost 100% success rate on the demanding task of using chopsticks to grasp small objects swinging in the air. We demonstrate the reactiveness, robustness and generalizability of CherryBot to varying object shapes and dynamics (e.g., external disturbances like wind and human perturbations). Videos are available at this URL.
